Home | Evolving Architecture
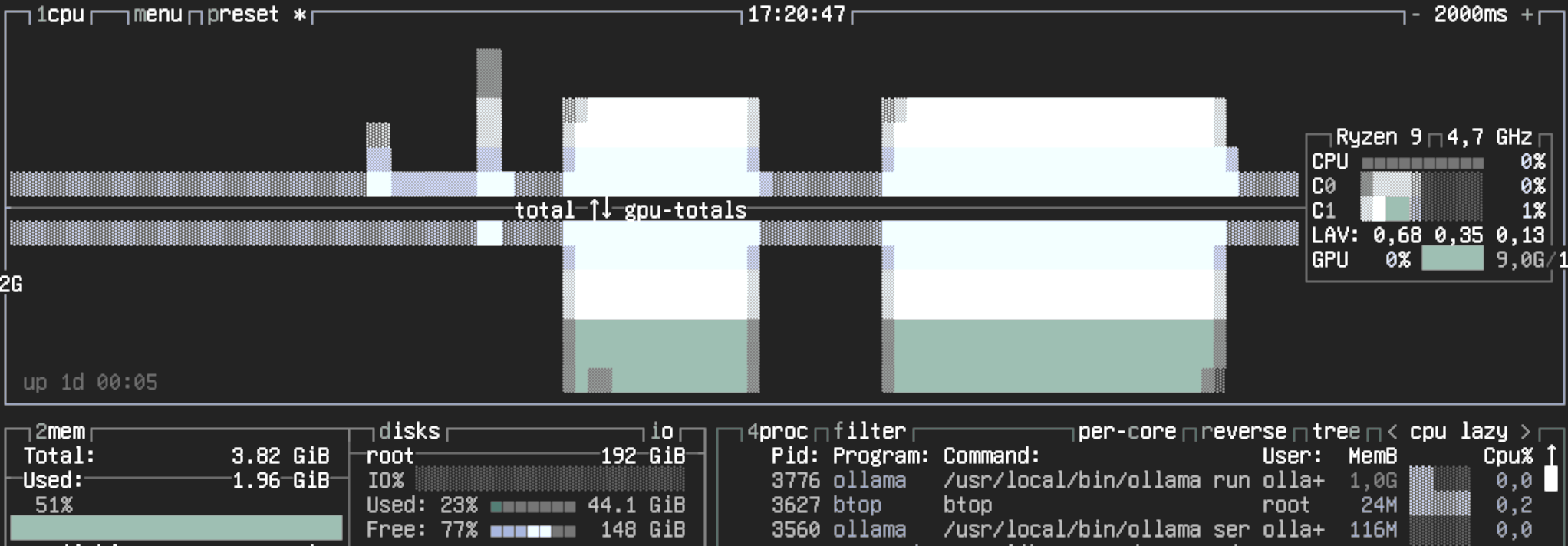
LLMs and “AI” are a hot topic, and despite the hype, there are practical applications that convinced me to invest my time and money
to set up a local LLM. This article isn’t about my use cases, but about the process of getting Ollama up and running with GPU
acceleration on FreeBSD using bhyve. This is a relatively advanced setup, requiring familiarity with FreeBSD, virtualization, and
NVIDIA drivers.
Initially, I explored running Ollama within a FreeBSD jail, but it only utilized CPU resources, quickly consuming all available
cores. To leverage my GeForce RTX 3060’s 12GB of RAM and GPU acceleration, I shifted to a Bhyve VM setup. I prefer running my
VMs with UEFI boot, as this makes migration to different hardware or hypervisors much easier. Let’s get started:
2025-08-15The hexagonal architecture helps to build robust and change friendly
code. I have used multiple different architecture paradigms over
the last 20+ years of writing software. For me the hexagonal
approach is the best when it comes to modern software engineering.
It can be used in all programming languages and helps to have
a sustainable software development effort over a long time.
Summary

The hexagonal architecture has many representations. It is usually
displayed as a hexagon that has three layers. Next to the layers there
is an east-west/left-right split.
2023-06-03This post details my experience with OpenBSD 7.3 on a SOPHOS sg105w Rev.1 from November 2014 as a router and firewall.
Preparation

The default BIOS settings didn’t let me install OpenBSD without issues. I got spammed with NMI Port messages.
The culprit it the BIOS CSM (compatibility support module) which I completely disabled. I configured the whole
system to use UEFI. I also enabled the speed stepping and enabled VMX/EPT.
2023-05-29In the previous post we discussed the importance of the unique ID for every record. Still we will update the records multiple times a day even if we don‘t change anything. Remember we scrape the data. Assuming 1Million records with 10 different sources e.g. and a scrape interval of 5 minutes we easily have a database load of 1M * 10 sources every 5m which equals to 120M rec/h which equals 33K req/s which has to potential to overload the database depending on the technology.
2023-03-18Deduplication of the data acquired in the distributed data pipeline is accomplished by using a common id. All records that are related to the same physical location need to end up having the same unique id.
Starting out, there are no unique ids. We only have data sources that can’t contribute data to any existing record. Looking back to the source A example from the previous post, we will start with only:
2023-02-19In this series I will detail a solution to a common problem with distributed data aggregation. We want to build a web application that displays current price and location data for EV charging stations on a map. The data is scraped from websites, sourced by the government or similar data sources. The here described solution has been in production for years. So it is known to solve the above problem.
2023-01-21